What Is AWS Auto Scaling?
AWS Auto Scaling is a cloud service that manages the scaling of resources in Amazon Web Services (AWS). By monitoring application performance and traffic patterns, it ensures that the necessary computing power is available when needed. This feature helps maintain a consistent application experience by adjusting computing resource levels in response to varying demands without human intervention.
Through AWS Auto Scaling, organizations can improve performance while reducing the risk of over-provisioning, which can lead to unnecessary costs. It allows for the dynamic scaling of applications, ensuring reliability and cost-effectiveness, and is useful for managing workloads efficiently in the cloud.
This is part of a series of articles about AWS cost.
Benefits of AWS Auto Scaling
AWS Auto Scaling helps organizations manage cloud resources efficiently by automatically adjusting demand-based capacity. Here are the key benefits:
- Optimized performance: Ensures applications run smoothly by automatically adjusting resources based on demand.
- Cost efficiency: Prevents over-provisioning by scaling down when demand is low, reducing unnecessary expenses.
- Improved availability: Maintains application uptime by quickly scaling up resources during traffic spikes.
- Automated management: Reduces manual effort by dynamically adjusting compute capacity based on predefined policies.
- Better fault tolerance: Replaces failed instances automatically, ensuring high availability and system resilience.
Source: AWS
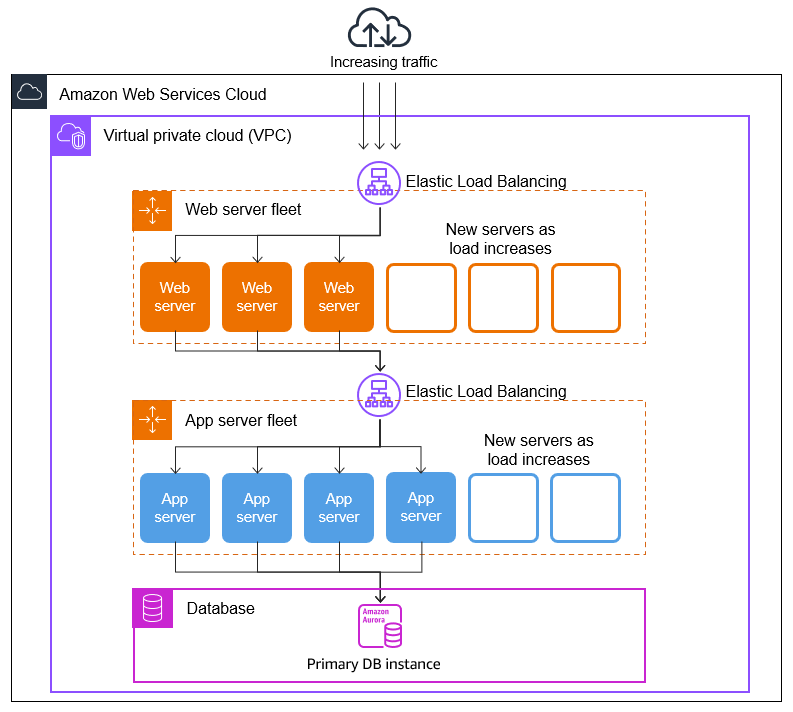
How AWS Auto Scaling Works
AWS Auto Scaling adjusts computing resources dynamically based on workload demands. It monitors performance metrics and makes real-time adjustments to ensure efficiency, cost-effectiveness, and high availability.
For Amazon EC2 instances, AWS Auto Scaling automatically launches new instances when demand increases and terminates excess instances when demand decreases. It also replaces unhealthy instances to maintain system resilience. This process is guided by predefined scaling policies that specify when and how resources should scale.
AWS Auto Scaling relies on Amazon CloudWatch to track performance metrics, such as CPU utilization. When a metric exceeds a defined threshold, CloudWatch triggers an alert, prompting AWS Auto Scaling to add more instances to handle the load. Similarly, when demand drops, the service scales down to prevent over-provisioning.
Related content: Read our guide to AWS cost optimization
Source: AWS

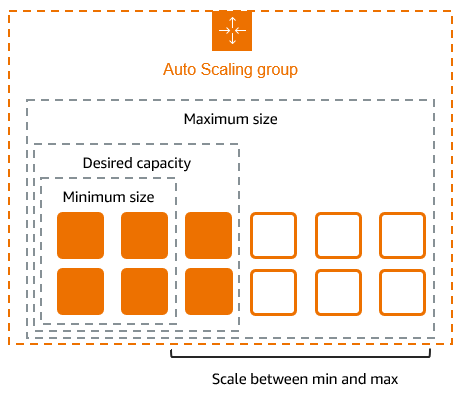
- Use multiple Auto Scaling groups for different workloads: Instead of having a single Auto Scaling group for all instances, split workloads into multiple groups based on different scaling needs. For example, keep stateless application servers in one group and database read replicas in another. This allows more granular control over scaling policies and better cost optimization.
- Incorporate custom metrics for smarter scaling: While AWS Auto Scaling primarily uses CPU and network utilization, you can integrate custom CloudWatch metrics like queue depth (for message processing apps) or request latency. This leads to more accurate scaling decisions tailored to the application’s real-world performance.
- Combine horizontal and vertical scaling for efficiency: Auto Scaling is typically used for horizontal scaling (adding/removing instances), but you can also automate vertical scaling by using EC2 Auto Scaling lifecycle hooks and AWS Systems Manager to upgrade/downgrade instance types dynamically based on demand.
- Optimize instance warm-up times: Configure instance warm-up settings properly to prevent premature scaling actions. If an instance takes longer to become operational (e.g., due to application startup processes), you can set a warm-up time in the scaling policy to avoid over-scaling.
- Implement lifecycle hooks for controlled instance termination: Use lifecycle hooks to manage instance termination gracefully. Before terminating an instance, trigger a script to deregister it from load balancers, move workloads to other instances, or save critical data. This helps maintain stability during scale-in events.
Types of Scaling in AWS Auto Scaling
Manual Scaling Methods
Manual scaling in AWS Auto Scaling requires users to actively adjust resource levels. This approach offers precise control over the number of running instances or resources based on anticipated demand. Although it requires hands-on intervention, it can be effective when loads are predictable, allowing exact resource allocation at specified times.
This method suits environments with stable, predictable workloads where automated scaling might not offer significant advantages. By enabling direct adjustments, manual scaling ensures users can optimize resources without automated processes, suitable for applications with consistent performance patterns. For example, a backend server with consistent workloads can be temporarily scaled down for a planned maintenance event.
Scheduled Scaling Techniques
Scheduled scaling in AWS Auto Scaling allows for resource adjustment based on anticipated demand patterns at specified times. Users can define scaling adjustments according to predictable cycles, such as peak business hours or regular maintenance periods. This ensures adequate resources are available without manual intervention during known traffic spikes.
By automating resource changes on a schedule on the AWS platform, organizations can manage predictable workloads. Scheduled scaling balances resource availability and cost efficiency, crucial for environments with repetitive demand cycles, ensuring optimal resource utilization.
Dynamic Scaling Policies
Dynamic scaling in AWS Auto Scaling automatically adjusts resources in real time based on current demand. This approach utilizes performance metrics to make informed scaling decisions, adding or removing instances as needed for optimal application performance. Dynamic scaling ensures resources align with changing demands, minimizing costs while maintaining service levels.
The ability to react instantly to demand changes makes dynamic scaling a vital component for applications experiencing variable traffic. Dynamic policies improve operational efficiency by automating resource adjustments, supporting agile environments that can adapt quickly to changes.
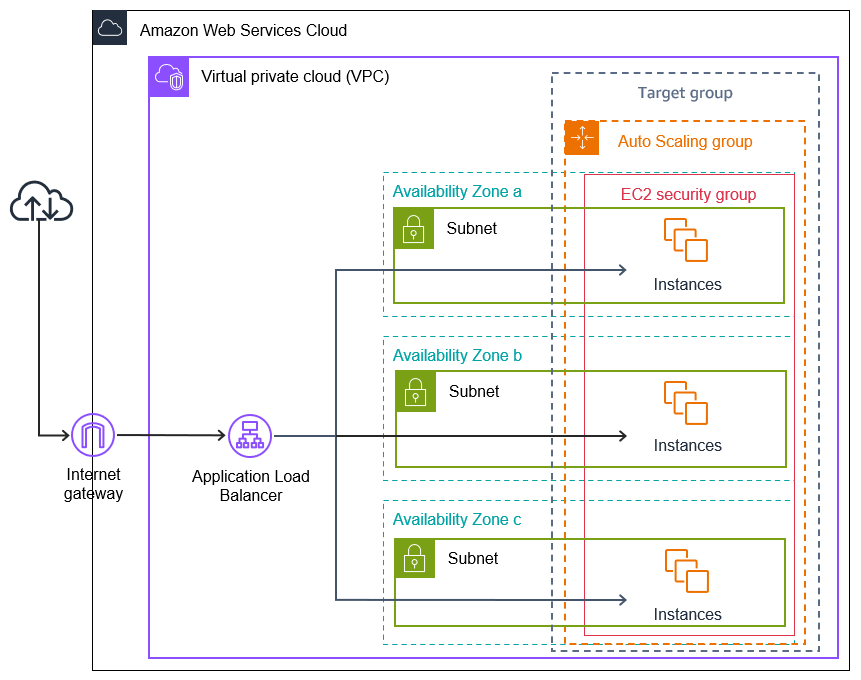
AWS Auto Scaling vs. Load Balancing
AWS Auto Scaling and load balancing serve different but complementary purposes in managing cloud resources efficiently. While AWS Auto Scaling adjusts the number of computing resources dynamically, load balancing ensures even distribution of traffic across available resources.
Key differences:
- Functionality: AWS Auto Scaling focuses on increasing or decreasing resource capacity based on demand, whereas load balancing distributes incoming traffic across multiple instances to prevent overload.
- Objective: Auto Scaling aims to optimize cost and performance by adding or removing resources as needed, while load balancing improves availability and fault tolerance by directing requests to healthy instances.
- Trigger Mechanism: Auto Scaling operates based on performance metrics (e.g., CPU utilization), scaling policies, or schedules. Load balancing, on the other hand, works continuously, routing requests in real time.
- Service Scope: Auto Scaling applies primarily to compute resources like EC2 instances, while load balancing supports broader resource types, including application and network layers.

Source: AWS
5 Best Practices for Effectively Using AWS Auto Scaling
Here are some of the ways that organizations can ensure the most effective use of AWS Auto Scaling.
1. Selecting Appropriate Instance Types
Choosing the right instance types is crucial for optimizing performance and cost efficiency. AWS provides various instance families tailored for compute, memory, storage, and GPU-intensive workloads. By selecting instances that align with workload requirements, organizations can prevent over-provisioning and underutilization.
To optimize scaling, consider using a mix of instance types within an Auto Scaling group. This approach, known as instance diversification, improves availability by ensuring workloads can run even if certain instance types become unavailable or expensive. AWS Compute Optimizer can provide recommendations on suitable instance types based on historical usage patterns.
2. Monitoring and Tuning Scaling Policies
Regularly reviewing and adjusting scaling policies ensures AWS Auto Scaling operates efficiently. Performance metrics, such as CPU utilization, memory usage, and request rates, should be monitored using Amazon CloudWatch to refine scaling thresholds.
Fine-tuning cooldown periods and adjusting step scaling or target tracking policies help prevent unnecessary scaling actions. For example, setting an optimal cooldown period prevents the system from adding or removing instances too quickly, avoiding unnecessary costs and instability. Periodic testing and analysis of historical performance data help in optimizing these settings.
3. Testing Auto Scaling Configurations
Before deploying Auto Scaling configurations in production, conducting thorough testing is essential. Simulating different traffic patterns helps evaluate how well scaling policies respond to varying loads. AWS provides tools like AWS Fault Injection Simulator (FIS) to test Auto Scaling behavior under failure conditions.
Load testing with services like AWS Performance Testing using Locust or Apache JMeter ensures that scaling triggers work as expected. Running controlled experiments allows for identifying potential bottlenecks and optimizing configurations before real-world deployment.
4. Utilizing Predictive Scaling Features
Predictive scaling uses machine learning models to forecast future demand and adjust resources in advance. This feature analyzes historical usage patterns to predict traffic trends, enabling proactive scaling. Unlike reactive scaling, which adjusts resources based on real-time changes, predictive scaling helps prevent resource shortages during peak demand periods.
Enabling predictive scaling through AWS Auto Scaling ensures smoother performance by reducing scaling lag. It works best for workloads with recurring traffic patterns, such as daily spikes in user activity or seasonal trends in eCommerce applications.
5. Integrating with AWS Spot Instances for Cost Savings
To reduce costs, organizations can incorporate AWS Spot Instances into their Auto Scaling groups. Spot Instances offer significant discounts compared to On-Demand Instances but may be interrupted by AWS when capacity is needed elsewhere.
By using a mix of On-Demand, Reserved, and Spot Instances, organizations can maintain cost efficiency while ensuring availability. Auto Scaling policies can be configured to prioritize Spot Instances while keeping fallback options available for uninterrupted operations. AWS Spot Fleet and EC2 Auto Scaling support instance diversification to minimize Spot Instance interruptions.
Optimizing Cost for AWS Auto Scaling with Umbrella
AWS Auto Scaling can help manage compute resources efficiently, but maximizing its cost-saving potential requires deeper visibility and smarter decision-making. That’s where a third-party cloud cost management platform can make a difference.
Umbrella helps FinOps, DevOps, and finance teams reduce cloud costs through intelligent data analysis with no long-term commitment required. As a native AWS integration offering, it simplifies your FinOps toolset while offering advanced savings opportunities beyond standard scaling policies.
With Umbrella, you gain:
- Hourly-level visibility into AWS Auto Scaling usage and costs through dynamic, customizable dashboards.
- 18–24 months of historical data retention, giving teams the context they need to make informed scaling and budgeting decisions.
- AI-powered budget projections and cost forecasts to anticipate cloud demand with greater accuracy — ideal for supporting or replacing predictive scaling.
- Multicloud and Kubernetes support, consolidating all your infrastructure spend into one unified view.
Additional features designed to enhance AWS Auto Scaling cost efficiency include:
- Real-time anomaly detection dashboards to quickly spot unusual cost spikes before they spiral.
- AI-powered recommendations for smarter instance selection, scaling policy tuning, and cost control.
- Personalized alerts that improve response times to unexpected usage changes.
- Forecasting tools that combine past usage patterns with machine learning to improve budget accuracy.
Umbrella helps AWS users avoid over-provisioning, minimize waste, and confidently scale with performance and cost visibility. Whether you’re managing one Auto Scaling group or dozens across regions and workloads, Umbrella equips your team with the insight and automation needed to scale smarter.
